An Introduction to Agile Estimation
Abstract
Traditional software development estimating techniques are slow, long lasting exercises and as such are totally unsuited to Agile processes. New methods of estimating have emerged which fit the Agile model, requiring minimal effort to provide ‘just enough’ information to support prioritization and decision making. This paper offers an introduction to the most popular of these techniques, as well as a look at how such practices work in larger, multi-team projects in which normalization has become the subject of disagreement.
Introduction
Traditional estimating techniques used in predictive, phased projects are meant to produce time estimates for tasks or related sets of requirements. Those of us who have sat through such estimation meetings, (often under the misnomer ‘planning’ meetings) will know what a painful experience this can be.
There are often endless discussions about how complex ‘X’ really is and how long it will take to code. The problem is that each task is considered independently of the others. It doesn’t help that each person tends to think about the problem from the perspective of doing the work themselves and naturally, degrees of (perceived and real) expertise vary from one individual to another.
Traditional Methods
Prior to the agile manifesto there were three primary methods in use traditionally for estimating work in software development projects:
- Bottom-Up Estimation – this was based around the concept of an ‘average developer’ doing a specific task, and the person doing the estimation trying to work out in isolation how much time it could take. For example, it would take me 5 hours to write this Java function, and I’m faster than my peers, so I’ll estimate 7 hours. It tended to create very large “bottom-up” estimates that were often challenged (reduced) by management, that then led to schedule problems down the road.
- Top-Down Estimation – this was based around the idea of ‘pattern matching’, i.e. you look at the project (or maybe a release of a project) in its entirety and compare its total size in terms of person hours with other similar projects. “This project is twice as complicated as the last project, which was 2,400 person hours, so we’ll estimate it as 4,800 person hours”. This tended to result in overly optimistic estimates that needed to be reconciled with a separate bottom up estimate.
- Function Point Estimation – This approach was often used to try and remove the human factor from the estimates (bias, optimism, etc.) and quantify the “size” of the work by a simple, quantitative metric. In the old days, it might be lines of code, but more commonly it was number of functions (e.g. software object methods or subroutines) being developed and a qualifying metric to account for it being a large, medium or small function. The result was a numerical value called “function points”. You could then use this metric together with a team-based time factor (e.g. this team can do 2.0 function points a day) to come up with a time estimate. This only worked when you had some prior development work to compare it against.
Agile Estimation Methods
Story Points
The human brain is far better at making comparisons than it is at making individual value judgments. You can usually identify the longer of two books, but accurately estimating how many pages either has is extremely difficult. This principle is the basis of the deceptively simple and yet highly successful device known as story points.

Story points are an abstract measure; they have no units. All we know is that 2 story points take twice as long to code and test as 1 story point, and 4 story points take twice as long as 2, and so on. That begs the question: How can we estimate something on the basis of an abstract measure? Further, how can we overcome the problem of individuals estimating based on their own individual abilities?
Estimation Methods
There are two popular estimating methods, both of which overcome these difficulties. Both share three key characteristics:
- All team members must participate,
- Only relative judgments will be made, and
- Each method is carried out as a game.
Planning Poker
The first method is referred to as ‘planning poker’ and was originally described by James Grenning (2002) and popularized by Mike Cohn in, ‘Agile Estimating and Planning’ (2005). The game goes something like this:
- A user story is read to the entire team, whereupon each team member estimates the number of story points without revealing his/her educated guess,
- All estimates are revealed at the same time,
- High and low estimates are explained by their proponents, with subsequent discussion,
- The secret estimation process is then repeated before returning to step 2.
Estimates usually converge quickly, but if one or two team members are unable to concur after repeated discussions, the majority view is taken. One other critical element of planning poker is the permissible values of the estimates, which can only be a number in the Fibonacci series: 1, 2, 3, 5, 8 or something similar to it such as the geometric progression 1, 2, 4, 8. This is because accurate value judgments are more difficult when things get larger. For example, when using only whole numbers, a 20% divergence from 1 is still 1; which is quick and easy. However, a 20% divergence from 8 is either 7 or 9, which becomes more difficult. Eliminating 7 or 9 as options makes the answer 8, which is again, quick and easy.
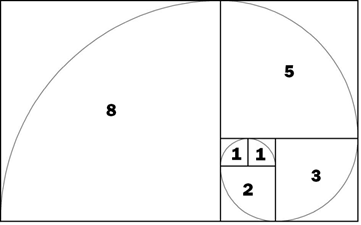
Figure 1: Fibonacci Series
This process ignores one key element. When the team estimates the very first story, how does each team member know what constitutes a single story point? There is no point (pun intended) of reference for them to use. Remember, we are using comparative methods, and with the very first story, there is nothing to compare it to. This catch-22 is solved by using a reference story. The team as a whole finds the smallest user story, (ignoring those requiring almost zero effort) and agrees to call that 1 story point. All subsequent estimates will be relative to that story. Occasional reminders of the reference story are a good idea to achieve consistency.
Two-Stage Estimating
The second estimation method avoids this problem by starting the process with the second story, not the first, thus making possible an immediate comparison. This method has two stages. In the first stage, the initial user story is placed in plain view, on a wall or table, for example. The first team member takes the next user story and places it:
- To the left of the first story, indicating that it requires less work than the first story,
- To the right, indicating that it requires more work, or
- Underneath another story, indicating that it requires about the same amount of work.
Each team member takes a turn placing a new user story relative to the others. Team members have one other option during their turn: they may move a previously placed story to another location if they disagree with the original placement. Play goes on until there are no more stories and nobody wants to rearrange the order. At this point, the stories have a relative order, but are not yet assigned story points. This is done in stage two.

Figure 2: Relative sizing
Stage two also requires a Fibonacci sequence, or something similar. The number 1 is placed above the leftmost story column, representing the smallest user story. The first team member takes the next number, 2, and places it above the stories he/she believes to be twice the work of the first column. This does not have to be the adjacent column of stories. The next player takes the next number and assigns it to a column of stories in the same way. Each player has one other option, which is to replace the previous number with theirs, e.g. they may feel that the stories assigned 5 may in fact be 8 and that there are no 5s and so 5 is not used. Optionally, the rules may allow a player to also move a user story after it has been assigned a number if it is now apparent that its position is wrong. Once all numbers have been placed and agreed, stories not located beneath numbers are collected beneath the previous number; they are effectively rounded down, not up.
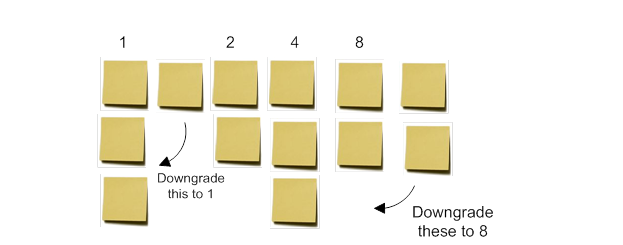
Figure 3: Assigning story points
In both games, the value zero can also be used in the case where the smallest user stories are really considered to be 30 minute tasks and can be rolled into others at little or no cost. Be aware that only a limited number of zero story point items will really be free. Too many and they will add up to one or more story points.
These estimation methods can be used before a project is in full swing when estimates are required for the backlog, (in Scrum terms) and when new stories are identified or existing stories change.
The next question is, how do we know how many story points we can assign to any iteration? This is where velocity comes in.
Velocity
Velocity is a measure of how many story points a team can implement in one iteration, based on previous performance. It is essential that story points and velocity remain abstract to avoid teams falling back into the old habits of absolute, time-based estimating.

But by inference, velocity does assign an absolute time value to a story point in the following way: take the number of days available to the entire team in an iteration, subtract non-coding/testing duties such as vacation, meetings, etc., and divide by the velocity. The result is the number of team person days per story point. For example:
- A team of 5 people potentially has 50 team days available per 2-week iteration,
- Each person spends, on average, 1 day per week in meetings, on vacation, or unavailable for other reasons, which is 2 days per iteration,
- Their velocity is 46.5.
50 – (5 x 2) / 46.5 = 0.86 team person days per story point
It is important to realize that the value ‘team person days’ is an average of all team members and that all team members must be participating in the iteration for the velocity to be meaningful. If 3 experienced coders are replaced with junior team members for an iteration, the expected velocity for that iteration must be reassessed.
While a story point time estimate can be easily calculated, it is not helpful to do so. In fact, it undermines the entire concept of story points because it leads back to the temptation to estimate based on the time required to complete a story, and as we shall see, there are many reasons why this is not good practice. The temptation is greatest for engineers new to Agile practices, and for managers who, despite working with Agile principles, feel rather uncomfortable without estimates of ‘man-days’ appearing somewhere in their plans.
Relating Story Points to Time
So, why don’t we relate story points directly to time so that we know how long each story point, and therefore each story, will take to complete? There are two major reasons, and both are related to velocity.
The first reason we don’t want to relate story points directly to time is that velocity is not constant, at least it shouldn’t be. As team members become more familiar with the project, the process, the environment and with each other, their productivity should go up. In other words, a team should show an increase in velocity as the project progresses. If we were directly relating story points to time, we could only ever assign the same number of story points for each iteration because the time available remains constant, whereas a variable and increasing velocity means the team is working faster and so we can assign more story points per iteration.
The second reason is critical on projects with multiple teams. Teams are not always the same size which, along with differing experience and expertise, affects how much work a team can do in one iteration. Thus, team velocities are rarely the same. A team with a greater velocity will complete more story points than one with a lower velocity. The differing velocities tell us how many story points we can assign to each team per iteration. If stories were measured by time, each story would need a separate time estimate for each team, each estimate being different, which is clearly absurd.
Having recognized that different teams have different velocities, we should also be able to conclude that the size of a story point may also vary from one team to another. Each team may have a consistent view of what a story point means to them, but across teams, story points may not be the same. This leaves us with a project reporting problem because it will not be possible to aggregate story points completed or planned across teams; they are using the same terminology, but not the same measures. It also means that velocities are not comparable across teams. A velocity of 7.5 might, in fact, be lower than one of 6.2 simply because the size of the first team’s story point is far smaller. All of this is fine provided each team has its own backlog and does its own estimates. Aside from reporting, teams operating entirely independently will not have a problem. But is this what we want?
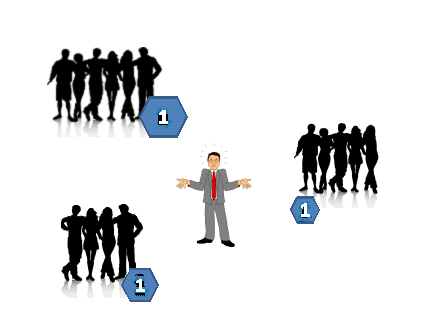
Figure 4: Story point size may differ across teams
To Normalize or not to Normalize?
Having totally autonomous teams reduces the flexibility that should exist in Agile projects to accommodate change and new user stories. Change may dictate that stories be transferred from one team to another. In fact, the job of the product owner would be far easier if he/she were able to allocate stories to teams dynamically as the project progresses, rather than dealing all the stories out to the teams at the start. To harmonize the teams and get them using the same estimation values they must have the same definition of a story point, which is achieved by a process called normalization.
There is no firm agreement within the Agile community as to whether normalization is a good or bad thing. Some say it is a waste of time and that up-front story allocation works perfectly well. Others say that teams need to be on the same page in order to achieve full agility and easier status reporting. While the debate continues, it is worth examining the methods of normalization.
Normalization Methods
To normalize estimation, the temptation is to yet again fall back on time; we all know what 1 day is, so why not use that as a common unit of measurement instead of story points? As soon as we do that, we lose all the benefits of relative estimating which we discussed earlier. However, without resorting to time estimation, we can still use the one-day-of-effort measure to bring a degree of consistency to the reference stories used by each team, against which they will compare the others.
- First, in a cross-team meeting, the definition of 1 day of effort is agreed by all, (accounting for vacations, administrative duties, meetings, etc.). This is sometimes called an Ideal Developer Day, or simply, Developer Day.
- Next, a 1 developer day reference story which fits the agreed definition is chosen by each team from stories they know well.
- Finally, the fact that this 1 story point reference was estimated as taking 1 day is forgotten and the story point once again becomes an abstract measure.
This process will not give perfect story point symmetry, but it will be close enough for stories to be transferable across teams and for aggregate reporting to be meaningful. It can also help individuals new to Agile processes to initially think of a story point as 1-day of effort, although the temptation to continue indefinitely with this way of thinking should be resisted.
If greater consistency is required, another normalization technique can be used which involves team representatives gathering for a common estimation meeting to identify stories for which they have an agreed understanding. They then estimate each story using the method chosen for the project, assigning story points to each. Optionally, each representative can first take the set of stories back to their team for estimation after which those results are used for estimating in the higher level meeting. This set of stories now provides a baseline of agreed estimates which is used by each team to calibrate their own estimating process. This meeting of the minds should occur before even the first iteration; before estimating begins, and then occasionally throughout the project to re-synchronize.
Remember, normalization is not mandatory and the effort required should only be expended if there is a belief that the benefits are worth it for the project: after all, in the end it’s all about return on investment (ROI.)
One final word about normalization. Some people think they are normalizing velocity across teams so that team performance can be compared. This is totally invalid. As we have shown, team sizes, experience and environments may vary greatly, so velocity should, and does, vary across teams and even for the same team over time, whether story points are normalized or not.
The “NoEstimation” Approach
Due to the problems with comparing estimates across teams, plus some research that found that simply counting all requirements or user stories equally (i.e. they are all the same size) resulting in project and release estimates that were statistically identical to using story points, there has been a move towards no estimates (#NoEstimate). This approach has been gaining traction in the industry in recent years.
In addition to the benefits to the team in terms of simplifying the planning process (no one particularly likes estimating work, let’s face it), using a simple count of user stories makes it much easier to compare across projects.
In fact, when we designed our SpiraPlan program and portfolio dashboards we ended up allowing users to roll up story points or simple counts to the Sprint, Release and Product levels, but only roll-up requirement counts to the program and portfolio levels. So, you can use a hybrid of estimation and no-estimation approaches in the same organization.

Summing Up
It must be remembered throughout all of these processes that estimation is not an end in itself and therefore under an Agile philosophy, as little effort as possible should be used in order to get the job done. Estimates are necessary for prioritization of the backlog and to achieve meaningful allocations for each iteration, but digging deep in an attempt to increase accuracy is wasteful. By doing so the user story begins to undergo analysis which should be part of implementation, not estimating and planning. As with many activities, the law of diminishing returns also applies to estimating; “don’t take too long, you’re not going to get significantly better results.”
Finally, the best estimates come from collective views of the entire team. Using only your managers or experts will tend to result in optimistic estimates. Conversely, using mostly individuals new to the team is likely to result in estimates larger than necessary. Include everyone; after all, it’s the Agile way.
Bibliography
http://scrummethodology.com/scrum-effort-estimation-and-story-points/
http://scaledagileframework.com
Cohn, Mike. Agile Estimating and Planning. Prentice-Hall, 2005.
Chris Sims & Hillary Louise Johnson. The Elements of Scrum. Dymaxicon, 2011
Dean Leffingwell. Agile Software Requirements. Addison-Wesley, 2011
