Abstract
Changes to requirements are usually one of the great headaches for software or systems development managers because first, the need for change cannot be ignored and second, minor changes can result in major impact. Whether working in an Agile environment, or with a traditional waterfall-type development process, change must not be allowed to run rampant but must be controlled so that the developing product benefits while the project is not adversely affected.
It is important to keep a record of change; what changed, when, why and who changed it. Requirements can have versions and baselines, but despite the same terminology, they are significantly different from versions and baselines typically managed by Configuration Management (CM) tools for just one reason: traceability.
Requirements Management (RM) tools can help enormously with the change and configuration of requirements and their relationships, indeed of all the dimensions of requirements management, change and configuration management are probably the most difficult, if not impossible, without software tool support.
When Requirements and Configuration Worlds Collide
Change is not only part of life, it is required for life. Anything that does not change is inert; lifeless. Software and systems projects are living entities which change, grow, shrink and adapt as events unfold. Because requirements are the basis for everything else that we do on a project, identifying, controlling, recording and reporting on their change is essential. When requirements management was a simple matter of writing MS-Word documents, (or WordPerfect… remember that?) or creating MS-Excel spreadsheets, it was easy to dump the entire document or spreadsheet into a configuration management (CM) system and be happy.
Making use of MS-Word reviewing features gives us some form of change documentation at the requirement statement level. But as requirements management has evolved beyond flat documents or simple spreadsheets these techniques have proven inadequate, especially the use of CM tools for requirements, which were never designed to manage information at the granularity of a single sentence, let alone a single word; something worth considering when it comes to requirements attribute changes.
As a result of this evolution, requirements management (RM) tools have been obliged to provide some degree of configuration management for the data they manage. The simplest approach is to make a straightforward record of all the changes that have taken place, but more useful is the concept of versioning and requirements baselining.
Because, (out of necessity) RM tools have developed their own CM capabilities, there is sometimes a conflict between RM and CM, both technically and within teams responsible for each. I have seen individuals with CM responsibility insist that requirements documents be held within the ‘approved’ corporate CM system despite the required reformatting of the requirements document which made it incompatible with the RM system itself. The problem is exacerbated when the RM system manages relationships between its own data and information in the CM tool, e.g. requirements linked to code. Taking this a step further, a good RM tool will also support links to the rest of the project, such as requirements to design and requirements to test. These relationships and their fine granularity are something most CM tools simply do not manage well.
To avoid confusion, conflict and wasted effort, it is imperative that individuals responsible for RM and those responsible for CM, put aside their egos and join together to provide an integrated solution that actually makes sense for the data and systems involved.
Changing Requirements in Agile Projects
Most things are managed incrementally in Agile projects, and requirements are no exception; the detailed analysis and fleshing out of the requirements does not all happen up front as it does with traditional development methods. Because much of the requirements work is still to be done while the system is already in development, change is looked upon more favorably than it would be otherwise. Moreover, change is actually encouraged in Agile projects as it is considered part of the drive for quality improvement; the idea being that upcoming requirements can be changed and adapted based on what the team, (including the stakeholders) learn in the preceding stages or iterations. In effect, we commit ourselves less until we see how the initial parts work, or don’t work, as the case may be.
The risk comes if we miss some important aspect of the requirements that seriously affects the design or architecture, simply because those requirements were not yet fleshed out. This could lead to significant changes to work already done. Equally, changes applied to requirements not yet chosen for implementation might introduce the need for a design or architecture change that would be costly. For this reason, it is still important for the development team to be informed of changes occurring and be given the chance to offer comments or objections. Consequently, change and configuration management of requirements is still an important element of Agile projects and the use of software tools to help with it can be greatly beneficial. Even if we decide not to use a formal change control process, it would be helpful to know who made a change and why after the fact, and so requirements change history continues to be a valuable asset.
Any contemporary project is highly unlikely to limit itself to textual requirements. Process flows, state diagrams, use cases, and other visualizations are all powerful alternatives that, although not exclusive to Agile projects, are certainly predominant in such environments. It is important to consider how to either record changes to graphical requirements, control changes to them, or both. Any requirements tool unable to adequately manage non-textual requirements is going to quickly become unhelpful or force a development team to confine itself to textual statements which is also a bad choice. Throughout this paper we shall be discussing requirements in a generic form and although not stating it specifically, we refer to requirements in all formats: textual, graphical, or otherwise.
Finally, formal management of change to requirements has a somewhat restrictive air about it which goes against the grain for Agile developers who promote self-management and greater freedoms for developers. We must strike the right balance between adaptability and easy changes on the one hand and the avoidance of excessive, disruptive changes on the other. The sensible use of RM tools to manage, (but not restrict) requirements change can help strike that balance.
Other Requirements-like Data
While this paper is primarily about requirements data, whether it be formal shall statements, use cases, mock-ups or any other form or type of expression, we should recognize that such flexibility in format means that we can really apply these ideas to almost any kind of information including design elements, tests and defect reports. The important distinctions we can make about requirements are that the data is generally very small, sometimes just a few words, and that to really be useful requirements need relationships, sometimes quite complex relationships. These distinctions separate our discussion from that of data such as code modules managed by a formal configuration management tool or general documentation managed by a word processor. Therefore, when we talk about using a requirements management software tool many of the concepts apply to other information that the tool might manage directly such as tests, or reference indirectly such as links to design entities managed elsewhere.
Requirements Change History
The simplest form of software assistance with requirements change is the recording of change history. The nice thing about recording history is that the business of requirements writing and editing is unaffected by this process, which takes place in the background. Benefits arise when we may need to look back to understand when and why a requirement was created or modified. Although word processors are generally inadequate as requirements management tools, they are generally quite capable of this level of record keeping. However, they offer little enforcement; should a user make a change without the necessary recording options active, (either deliberately or inadvertently) there would be no trace of the change. The inclusion of a CM tool to force the recording of historical variants of the requirements documents can help in a simple case such as this, but it can become burdensome and perhaps more trouble than it is worth for some projects.
One of the benefits of making changes in a word processor is that most offer the ability to show exactly what has changed, letter by letter, word by word, making the review process an easier one. Unless we choose an RM tool that does the same, it will be seen as a clear step back by those who are being asked to transition from word processing to an RM tool. We also have the ever constant problem of word processors simply being unsuitable for requirements information for a host of reasons including the lack of attributes or easy linking mechanisms; however the detailed pros and cons of word processors for requirements management are outside the scope of this paper.
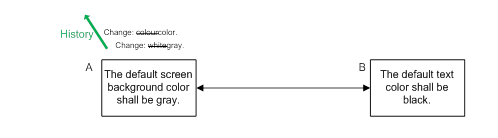
It is useful to note that a record of history is all that is required to be able to affect an ‘undo’ function. If we are not using a formal RM tool, the change history in a word processor will at least allow us to make an accurate reversal and return to a previous value. Be aware though, that an undo without the detailed context that an RM tool offers, can result in a requirement which as a whole makes no sense, or worse makes sense but is not at all what we would expect. For example, undoing the edit of the requirements text so that the color in Figure 1 returns to white, is fine, unless we examine the details of the requirement and see that there is an associated information attribute which says, “Shades of gray are easier on the eye”.

Figure 1: Recording history as individual changes
In order to fully report on a past change, the system being used needs to know who each user is. A further benefit of most RM tools is that they require users to authenticate, and therefore they can confidently record the name of any user making a change, whereas the identification of users by word processors is rarely reliable.
One further difficulty that arises with historical requirements is in the ability to access the record of deleted information.
The History of Deleted Requirements
The problem with deleted information of any kind is that is it no longer there. Well, ‘that’s the point’, I hear you say, and yes, that is the point. However, sometimes we need to know what used to be there but isn’t anymore. A feature becomes part of the design, but then team members with greater influence have a change of heart and the requirement is eliminated. If we are trying to fully understand the design as it exists, we would need to see the deleted requirement, at least until the point when the design is modified to reflect the deletion. Sometimes this is managed by not actually deleting the information at all but instead labeling it as deleted, which we can do even if we are managing requirements with something as simple as a spreadsheet. In this case, we must remember, when trying to look at the current state of affairs, to remove all artifacts labeled as deleted. Sometimes this oversight is obvious, such as when there is a clear replacement for the deleted requirement and we see each one next to the other, but we can’t rely on that. Some automated RM tools hide deleted objects and remove them from all consideration unless the user explicitly asks for deleted objects to be considered. This is convenient because it appears as though the requirement was deleted and the system acts as though it is deleted, but it remains hidden until such time as we might want it. When tools do not provide such management of deletions we must be careful to provide some manual process to accommodate those scenarios, and this can be fraught with difficulty.
The same is true of relationships. While two artifacts might be linked at one time, their relationship may become obsolete and need removing. When this happens, it would be nice to have an easily accessible record of the link’s previous existence, when it was removed and by whom.
As with most aspects of requirements configuration and change management, it is relationships which truly complicate matters when it comes to deletion. If one end of a relationship is deleted, what happens to the relationship itself? Should it also be deleted? Should it become a ‘dangling’ link with only one true end? Should it still point to or from the ghost of the deleted requirement, (if there is one)? There is no right or wrong answer to these questions. The most important thing is that we are aware of the questions and we examine the issue and decide on a course of action of which everyone is aware. Some automated tools warn users when they try to delete an object with a link attached while others simple will not let the artifact be deleted until all its links have been resolved. Help from an automated RM tool is certainly desirable, but exactly which kind of help is the best may simple be a matter of preference.
With all these deleted artifacts floating about, the data could become rather large and potentially cumbersome. This can be overcome by taking advantage of baselines. Although we have not discussed baselines yet, it is worth noting here that if a baseline also captures information about deleted requirements, links, etc., then it is often unnecessary to keep deleted information in the current dataset any longer.
Change history provides visibility into the past life of requirements, but offers no means of reference to a full and complete view of requirements as they were in the past. For that, we need to either take the pieces of history and manually reconstruct the requirement or we need to have automated version management.
Requirements Version Management
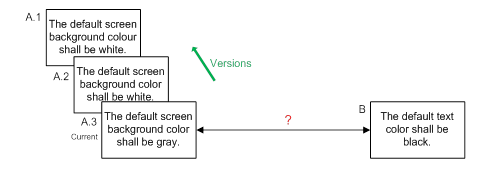
The difference between keeping history and keeping versions is that with the latter we have the entire requirement entity, including attributes, properties and any other data which makes up the requirement. History only gives us the change made to one aspect of the requirement, usually the requirement text itself. (Note: versioning can be implemented either by true copies of entire requirements, or by clever manipulation of change history to give the appearance of complete requirements copies. For the purpose of this discussion it does not matter which method is being used under the covers, we are merely concerned with the apparent versioning of whole requirements and the associated benefits that it provides.)
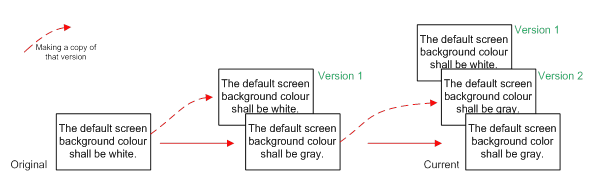
Figure 2: Recording history as versions of requirements
The benefit of having the entire requirement entity is that we can see the context of history. The attacks on the Japanese by the USA in the World War II might seem unprovoked without the context of the Japanese attack on Pearl Harbor. Although less dramatic, the understanding of requirements history is affected by context in the same way. As we shall see later, the context provided by relationships can be even more significant.
As we saw with requirements history, undo can cause inconsistent results, but reverting to an entire requirement entity should at least provide a consistent and meaningful individual requirement (we still have the overall project context to consider which we shall do when we examine relationships).
The most important aspect of full versioning is that it is a prerequisite for baselining and product family management (PFM).
Requirements Baselining
A baseline is nothing more than a collection of versions, frozen so that they may not be altered. Baselining a meaningful set of requirements allows a team to work on a stable set of information without necessarily stifling change at the same time. Work can progress against the baselines while new changes may apply to the current, non-baselined data. A perfect example is an Agile project in which a team can begin working on a set of baselined requirements for a development iteration while those requirements continue to evolve and grow ready for the next iteration. The baselines become a complete definition of the entire system at each build point and possible release, incrementally growing with each iteration’s new requirements as well as including any changes made to previously implemented requirements. We can also add requirements related data such as designs, tests, defects, etc. into the baseline, although here things become tricky due to the baselining or versioning of relationships and the interaction with any other repositories of the related information and any other tools involved. The interaction with other repositories will rely upon the capability of the specific tools we are using, suffice to say that this is far easier to get to grips with if our RM tool provides integrations with design tools, test management capabilities, etc. It is not something that should be tackled manually or with something simple such as a word processor or spreadsheet.
Baseline Hierarchies
As we said, a baseline is made up of a number of artifacts, or requirements in our case, one version of each requirement as seen in Figure 3. But we can also make baselines of baselines. This is not merely a mechanism for collecting multiple baselines together; when it comes to requirements traceability, it is the mechanism that creates the full historical picture. Requirements within a single set, such as user requirements, do not often have traceability between them.
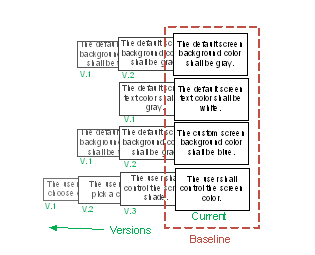
Figure 3: Creating a Baseline from Current Versions
It is much more likely that requirements trace to statements of greater detail or to other types of artifacts such as test cases or defects. If we separately baseline the groups of common requirements such as user requirements and test cases, we are not going to capture the relationship information that goes between those groups, because the links lie outside each baseline boundary, and thus we have no relationship history, see Figure 4.
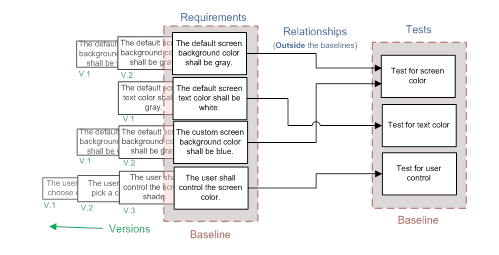
Figure 4: Relationships Lying Outside Baselines
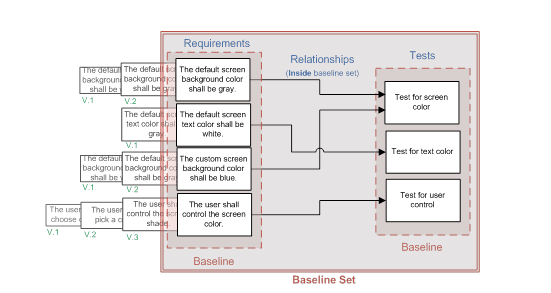
To fully capture relationships in baselines we must create one larger baseline of all the other baselines combined so that the links then lie inside that baseline. While it would be possible to not create the smaller baselines and instead make the entire project one baseline, it simply isn’t practical to manage that volume of data in that way. Once we create an all encompassing baseline set we end up with a hierarchy of historical artifacts which looks something like that in Figure 5. With this process, we shall be able to go back to the baseline set and see not only what the requirements and tests looked like at that milestone but also what the relationships were between them.

Figure 5: Relationships Captured in a Baseline Set
Contrary to popular belief, a baseline does not have to represent a single point in time and this is often impractical as the requirements, (or other data) we need to include in the baseline are rarely ready at the same time. We could make some pieces wait until the others catch up, but then we would be imposing unnecessary delays on parts of the project. A better definition of a baseline is a set of data that belongs together in a common evolutionary context. This context often represents a particular state that the requirements have reached such as being ready for review or having been approved.
Incremental Baselines
To produce baselines containing artifacts that have matured at different times, the baselines can be created incrementally, provided we have a clear definition of what the baseline means. Incremental or progressive baselines are especially helpful within processes such as Kanban where there are no clear iterations and tasks begin and end at their own pace. The granularity at which we add data to the baseline is theoretically a matter of choice, however there are practical considerations. If the granularity is too fine, the degree of effort required to manage the build-up of the baseline is too great. If the granularity is too coarse, we lose many of the benefits of incremental baselines as we return to the state of waiting for things to catch up. The most effective grouping of requirements for baselining is around information of similar applicability, for example, user requirements for a specific functional area or requirements selected for the same iteration.
At some point all the relevant information will have been added to the baseline and it can be considered complete. We will need to change its state from ‘open’ to ‘closed’, or ‘complete’. Bear in mind that the purpose of an open baseline is to allow work to continue while still placing a line in the sand. As work is continuing, it is entirely possible that the latest work might reach a point where it can be added to a new incremental baseline, even while the first is still open and actively accumulating more data. Support for multiple concurrent incremental baselines in an RM tool, far from being just a fancy gimmick, is a reflection of how things actually proceed in the real world.
When we discussed versioning, we touched on the undo function as it applies to requirements edits. It shouldn’t be too great a leap to see that we can apply an undo to an entire baseline should we choose to do so. This might be a drastic measure, but sometimes, in the face of serious development error, it can save more time and effort to revert to the last baseline and do it all again, than to try to fix the problem. While this is generally more applicable to design and code, the requirements and related data should be rolled back to the same baseline point as any code or design being reversed. Just remember that when rolling back requirements, it is important to be sure that the links still make sense. Do we roll back the links with the requirements or keep the current links that relate to other data? Either way, there is a serious risk of mismatch. The safest solution is to declare all links between the current data and the recovered data to be suspect (see Suspect Objects, below.) However, we can refine this with an educated guess and say that the links are still accurate where requirements are the same before and after the recovery.
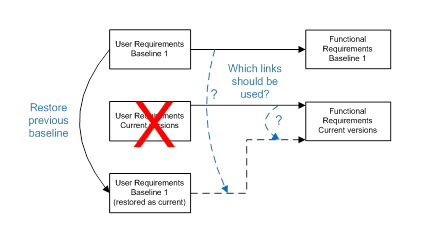
Figure 6: What Should Happen to Links When Restoring Requirements Baselines?
Baseline Compare
Another benefit of baselines worth mentioning is the ability to highlight the differences between one important milestone and another, whether the milestone is a point in time or a conceptual point such as an agreed feature set. In the same way that a CM tool shows the difference in code between baselines, a RM tool should show the difference between requirements, but beyond that it should also show changes in relationships. This information should be as easily accessible for adjacent baselines as it is for those that are multiple baselines apart.
Branching and Merging
Parallel baselines are a practical reality, which becomes patently obvious once we make a release of software to users. Release #1 goes out into the real world to live or die while our project continues to work towards release #2. But as almost always happens, some defect is discovered that users cannot live with for long, at least not until release #2 is ready. So, as almost all of us are required to do at some point or other, we plan a patch, or intermediate update. We decide that the fixes required apply to the released product only, not the work in progress, and so we must go back to the baseline related to the release. This is no different from the way we would handle the code for a patch, the only differences are those we have discussed: granularity, relationships and the tools we might be using. As with CM tools, we need the concept of a branch to the baseline that can later be merged with the current versions so that the fix also applies to the next full release.
Perhaps it might now be clear that almost everything we would do with a CM tool to manage configurations of code we also need to do to configurations of requirements. It is not for lack of trying, that RM tool vendors have failed to devise a good way to harness the capabilities of CM tools and apply them to requirements. In theory, this would make many of the problems we are discussing would go away, but until CM tools can efficiently manage the fine granularity of requirements and their attributes, as well as the complexity of relationships, RM tools will need to continue providing these capabilities themselves.
The ability to branch a set of requirements is key to effective Product Family Management (PFM), which is, as the name suggests, the practice of managing multiple products based on a core competency. Variants of a car or a smartphone can be efficiently managed by reusing a common set of requirements from which all variations evolve. While PFM requires some sophisticated version and baseline management, it incorporates a number of other techniques outside the scope of this paper and being a sizable topic in its own right, we shall leave PFM for another day.
The Impact of Change on Relationships
Suspect Objects
The greatest challenge relating to requirements versioning is the management over time of the relationships between those requirements. If we are merely keeping track of the changes to requirements, i.e. the change history, then the solution is relatively straightforward. As there are never any historical copies of the requirements the only artifacts that can be linked are the current ones. The relationship remains in place no matter how many times the requirements are changed. However, the relationship can still help by providing impact information. Let’s consider the following example of two simple requirements which have a clear interaction. These requirements may be too detailed for some projects, especially projects that are following an Agile process, however the principles we are discussing apply regardless of the detail of the requirements themselves.

If requirement A is changed, the relationship tells us that we should examine B to see whether it too needs to be modified to match the new version of A. This is the clearest example of why we need relationships in the first place. Without them, we would rely on one person having sufficiently detailed knowledge of the system to realize that B needs to be reviewed when A is changed, which is not only asking a lot but is also extremely error prone. Herein lies the danger of taking Agile development principles too far and relying solely on information posted on a board for all to see. The small number of requirements being worked at any one time might be manageable, but there are all the requirements that went before, and all those to come; managing those manually is impractical. Some form of automation is necessary.
If we choose to use a non-specific software tool such as a spreadsheet, we can keep track of relationships, but we must remember to check all of them for every change that occurs. This is doable, but can be arduous and still prone to error. We could miss a link, forget to check, or in our haste, decide that we know the system well enough to make the call without checking. Surprisingly, this problem can also exist for custom made software tools, even those specifically designed for requirements management. If relationships in such tools are inert, we must remember to check them all manually following any change. A truly useful requirements management tool provides active links that help us identify the requirements that need to be reviewed after a change. Most products call this feature, ‘suspect links’, although the term implies that the entire link is brought into question whenever a change occurs. In reality, the link usually remains relevant; it is the details of the requirement at the other end which are in doubt and so a more appropriate term would be ‘suspect requirements’. In our example, a change to A has no affect on the relationship, but there could be a very important impact on B. As this principle applies to all types of data, not just requirements, we should instead use the term ‘suspect objects’.
Suspect objects is one of the most powerful features of requirements management automation and will help reduce, if not eliminate altogether, the chance of missing any impact errors due to change. The only caveat is that the suspect objects feature is only as good as the relationships created within the data: no link - no suspect object.
The means of alerting the user of suspect objects varies from tool to tool, with the better tools providing the alerts through views used on a regular basis. Requiring the user to go look for suspect object notifications defeats the purpose.
Versioning Relationships
Life is relatively simple when we only record changes to each requirement. Whether we are using a spreadsheet or a formal RM tool, the only objects that exist are the current requirements themselves and therefore those are the only things that can be linked.
On the other hand, if we keep copies of each version of each requirement, then we find that to keep track of what has happened, we need to assign version numbers to requirements. Also, now that we have different versions of requirements, we must decide what to do about relationships.
The simplest thing to do, (and therefore most RM tools do this) is to only support links between current versions, not older versions. However, from a configuration management standpoint, this is weak as it does not truly represent the link in an accurate historical context. It is as though we are trying to rewrite history to say the link was actually created between the two current requirements. Recording the creation date of the link can help, but that leaves the user trying to match the link date with the requirement dates to see what the information really means.
To represent the history of the data accurately, we would need to take a snapshot of the two requirements and their link at the point before B was edited; this would give us a record of before and after. However, B may be linked to C, which may be linked to D, and so on, and therefore in order to truly represent the system before and after each change, we would need to take a snapshot of the entire system whenever we make a change to a single requirement. This is clearly impractical and so we need a different solution.
Let’s look at the problem step by step. We’ll use the same example where the requirements reflect contrasting colors between the text and the background.
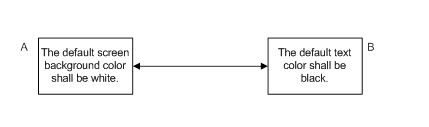
Now, we shall edit B. The relationship we originally created was between the requirements reflecting the original contrasting colors, and so the requirements and relationships should really look like this:
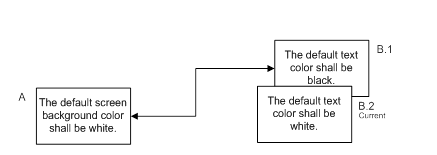
This leaves us with no link to the current version of B, which also cannot be right. Another option is to have two links, one to the original requirement, and a copy of it to the new version of the requirement. This also seems inherently wrong, because we are trying to represent the past and the present with a single structure. The truth is that there is no ‘right’ answer to the problem, at least not at this level of granularity and some software tools do not try to resolve the issue, relying instead on the user to regulate the changes in links as the requirements at either end are modified. In some ways this is the safest approach as all automated solutions either make assumptions which may not be correct, or the implementation can be complex, requiring a clear understanding by the user of the tool’s internal process in order to avoid considerable confusion.
Regardless of how we address this problem, we must still be fully aware of the impact of change and so we still need some kind of suspect objects capability. If a tool is really helpful, it will not only notify the user of the suspect object, but offer the option to automatically either leave the link pointing to the older version or transfer the link to the new, current version.
As is happens, the problem is far easier to manage if we consider changes in groups, rather than individually. If A and B are changed at the same time, (or at least as a organic set) not only is there greater chance that they are changed in a consistent and meaningful way, but we can now manipulate the links sensibly in order to reflect both the present and the past. The version 1 requirements are linked, as are the version 2, or current version requirements.
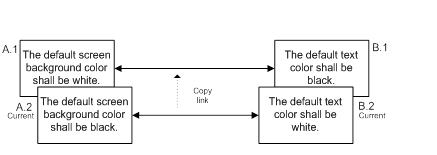
From this we can see that rather than making changes piecemeal, combining changes into groups can be very powerful, especially where there are logical relationships between requirements or objects. Natural groupings exist in most projects in the form of baselines. Within Agile projects such as those following a Scrum process, the iteration or sprint also creates a natural set of requirements and related information in which changes can be grouped.
Incremental Baselining of Relationships
Simultaneous change for a set of data is a practical solution for a set of localized requirements, but is quite unworkable when it comes to lifecycle traceability where we may have chains of relationships stretching from the user requirements through to the acceptance tests. Expecting change to occur simultaneously across the lifecycle, or even for a part of it, is unrealistic. Change works like falling dominoes; the dominoes do not fall together, rather there is a series of events, one after the other. Although the process is involved, it is possible to manage links between the falling dominoes automatically, so that as each domino falls, the links are transformed until all the changes are complete and a consistent set of relationships emerges. Let’s consider an example in which work progresses across the lifecycle and as it does so, each set of data is separately baselined, each subsequent baseline representing another falling domino.
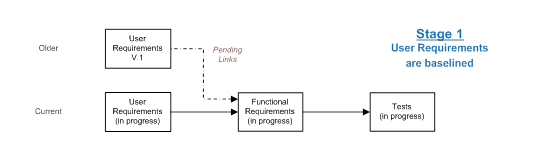
After the set of user requirements is baselined as version 1 there are, as yet, no version 1 functional requirements to link to, and so we create pending links as copies of the current links which then wait for the functional requirements to catch up. When the functional requirements are later baselined, those pending links become real and transfer to the new baseline of functional requirements. In turn, pending links are created to the tests, until they too are ready to be baselined.
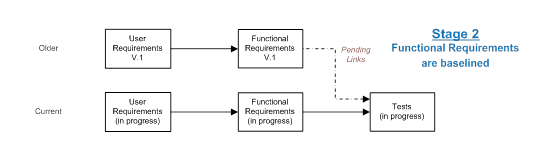
Finally, the tests will catch up, the process repeats, and a full, coherent baseline of all the project data exists, complete with meaningful links. Importantly, there is no reason why another baseline set cannot start before the first is complete. Indeed, we can have as many concurrent iterations in progress as necessary.
This process is very close to the concepts we discussed for baseline sets, where baselines are added to the set incrementally, capturing the relationships as each new subset of baseline data is added until the full baseline set is complete.
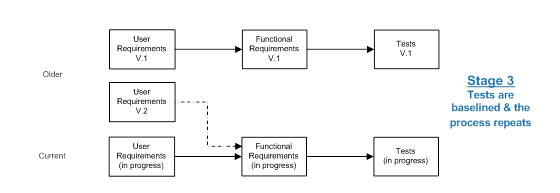
For some projects this level of relationship management is excessive, however it is important to realize that if links between artifacts are not changing as the artifacts change, the relationship information represented by the link can easily become stale and no longer truly represent how the current versions of the requirements or other artifacts are related.
Note: this problem does not occur in a CM system when baselining something like code as a code baseline is just one big pot into which all the code is thrown until the pot is full and the configuration is complete. There are usually no explicit relationships between the code elements, they just all belong together. In some cases, detailed relationships between code artifacts may define elsewhere but such relationships are not generally part of the code itself.
Requirements Change Management
It is one thing to keep track of information relating to changes that have occurred, but it is another thing entirely to manage the process of change itself. Some projects are subject to tight regulation, others have serious financial constraints, some have contractual limitations on change while others are developing software or systems with critical, potentially life-threatening consequences of failure. Such projects are candidates for change management at the requirements level.
While projects like the ones described above can certainly benefit from Agile practices, they will usually require tighter control of the requirements list or stack than pure Agile processes would advocate. There is no reason why tight requirements change control should not be used in an Agile process, provided it confines itself to the management of requirements changes and not to the determination of which requirements in the list will be implemented next. To do so would undermine the lightweight and flexible nature of the Agile process. We shall examine the change management process without prejudice towards the type of project in which it is to be applied.
Whether a change comes from the product owner, the paying customer, a user or from an idea within the project team itself, it would be shortsighted to ignore it. At the same time, we cannot let change run rampant. Purely manual change management processes are time consuming and subject to error and so tool support for requirements change management is highly desirable. As well as handling direct changes, an automated change management system (CMS) can provide a portal for ideas, suggestions and simple “what-ifs”. Making a CMS accessible to all team members ensures that we don’t lose ideas and helps prevent anyone from feeling disenfranchised.
A CMS should support changes to existing requirements and proposals for requirements to be created or deleted. Change or delete requests work best if they allow the user to see the requirement against which the proposal is being made and then seemingly ‘edit’ the requirement to create the change proposal. The CMS should also allow the user to enter the true source of the suggestion, e.g. a specific user, some competitive information or just a dream he or she had last night! There should also be the ability to enter a reason as plain suggestions are rarely self-explanatory. Some indication of urgency, priority or importance is useful but not essential. Let’s not forget that changes will occur to individual attributes and those changes may be as important as the requirement test itself; a change in priority will almost certainly have an impact on the project itself. A good CMS will provide a change process for all requirements information whether it is text, attribute or even a graphical requirement. A really powerful automated CMS will also allow proposals for the change, creation, or deletion of relationships; however for the majority of projects this level of detail is unnecessary.
How we proceed to process a change varies from one CMS to another. Options include the ability to collect multiple approvals from other users, notification to key users that changes are pending as well as quick and simple displays of the impact of a change. Once a change has been approved it is important, for reasons we saw earlier, to allow changes to be grouped together and applied simultaneously.
One issue that is often overlooked concerns stale proposals. A requirement that has been edited since a change proposal for it was submitted, has potentially nullified the proposal and should be flagged as needing attention. Reviewing the proposal might then be confusing, or worse, applying the change may overwrite the prior change without anybody noticing. The combination of a change proposal against a requirement attribute and the subsequent edit of the requirement itself is not, on the face of it, a conflict, but there is the significant risk of incongruity. All these scenarios can be avoided by using access controls to prevent manual changes when a group of requirements is under change management, however this results in excessive control in many cases. A simpler solution is to have the CMS provide a warning whenever viewing or trying to apply a change that is effectively out of date, or stale.
Whether using a CMS or not, change notification can be a powerful feature to keep a team informed, especially when that team is not co-located. The best notification systems are integrated into existing social media such as twitter, or simply email, rather than providing some communication system of their own. Information overload should also be avoided by limiting the people who need to be notified of changes. In an Agile project, development team members rarely need to know that a change has occurred to requirements not in the current workload, whereas product owners, stakeholders and architects would likely be interested.
One final aspect of change management systems worth mentioning is electronic signature. Some regulatory bodies such as the Food & Drug Administration (FDA) require electronic signature for such things as approvals, requirements acceptance or even requirements change. The mechanism of achieving the signature is not really relevant, (it might be a sophisticated biometric device, or a simple id and password entry) but it is important that electronic signature be incorporated into the process in a way that can be helpful rather than an additional headache for the team.
As with all automated systems, it is important to choose a change management solution that is sufficiently helpful without being overly burdensome.
Summary
The story of changing requirements is the story of how traceability makes everything more complicated. Keeping track of two items as they each change is difficult enough, but trying to keep track of them both and the relationship between them while they are changing independently from one another becomes something akin to herding cats. Never take lightly the importance of change management, versioning and baselining of requirements and traceability and never underestimate the difficulty of managing it all without the support of a software tool.
