March 23rd, 2021 by Thea Maisuradze
Estimation has always been an inflection point in the software engineering world. Many developers admit that one of the hardest parts of their job is not about naming things or invalidating caches (as the old saying goes) but giving estimates. Certainly, for many experienced software engineers, estimates have always been the most frequent area of friction between software developers and managers. Both sides seem to have valid arguments: managers want to know how long things will take, as they need to manage budgets and customer expectations. Developers, on the other hand, know that most software tasks cannot be estimated accurately enough to satisfy the manager's needs. This friction has been so intense that it's given rise to the #NoEstimates movement and many flame wars on social media. But is the choice truly between one of these two extreme positions, or can a happy medium be found that satisfies both sides?
This series of articles attempts to explore and answer this question.
Current Agile Approaches to Estimation
Estimating is what you do when you don't know
-- Sherman Kent, a.k.a "the father of intelligence analysis"
Estimation is all about risk management - that is, predicting the impact of the "known unknowns" and allowing for the
'unknown unknowns," as Donald Rumsfeld once stated. The Scrum framework attempts to mitigate these unknowns' risks (among other things) by prescribing an iterative and incremental development life cycle. A Sprint lasts no more than a month. At the Sprint Planning event, the Scrum team will be called to decide how many Product Backlog items it can deliver within the Sprint. The items selected for the Sprint should have a level of detail adequate enough for the team to estimate their size or complexity. The short horizon and focused delivery established by the Sprint means that estimates are given within the narrow end of the Cone of Uncertainty. The cone of uncertainty is the graphical depiction of an important estimation axiom: Estimates are more accurate the closer they are to the point of delivery.
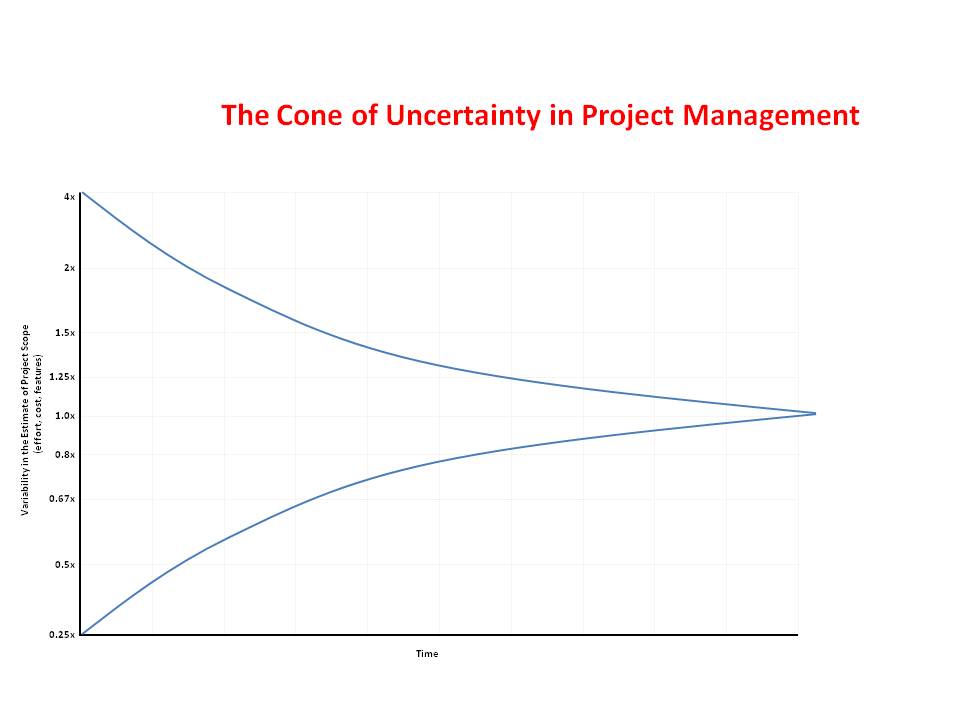
It is self-evident that the estimate we give for an item at the start of the Sprint will not be as accurate as the estimate for the same item half-way through the sprint. It is also obvious that estimates for more longer-term events, such as release planning or product roadmaps, will have an even greater margin of error.
Generally speaking, there are two main estimation approaches in the agile world:
- Relativistic estimation - where work items are estimated in relation to one another. This is the most widely used estimation method among Scrum Teams. It is commonly known as Planning Poker, Story Sizing, Bucket Listing, Dot Voting, and other names.
- Probabilistic estimation - this relies on historical data, on which they apply statistical sampling techniques to establish time-ranges or confidence intervals for the completion of work items. Instead of producing an average value of 'size' for an item, as we do with relativistic methods, with probabilistic techniques, we can produce time-ranges for which we can expect the item to be completed with a certain confidence level.
Relativistic methods come naturally to most people and are usually easiest to apply. In this series of articles, we'll look at the efficacy of such methods and discuss improvements.
Planning Poker and Friends
Relativistic methods are all based on the same principle: the team provides an estimate (or size) of a work item relative to the size of other work items. Most of the relativistic approaches employ a scale (usually a Fibonacci series) and one or more baseline values to denote the 'smaller' and 'larger' items. The estimate values assigned to an item are usually called 'story points,' as most work items as expressed as user stories. The way estimation is performed is normally along these lines:
- Each developer has a deck of cards representing all values of the estimation scale.
- Product Owner reads out backlog item and answers questions about it
- Developers think about the item and privately decide on an estimate based on the established scale
- Developers simultaneously announce their story-point estimates (or show their cards)
- Developers give reasons for their assigned estimates and discuss them
- Steps 3-5 are repeated until consensus on a single story-point value is achieved for the item.
The sum of story points a Scrum Team can deliver during a Sprint is known as the team's *velocity* and serves as a metric of the team's work cadence and to make longer-term forecasting.
Planning poker and similar methods are a great way to generate discussion and analysis of work items or tasks. However, experience shows that they are a poor way to estimate things. They can be described as 'finger-in-the-air' methods because they are like trying to guess the wind's speed and direction by putting a wet finger up in the air. A very experienced outdoorsy person may give a reasonable estimate, but most people will get it horribly wrong. Let me explain why planning poker and the like are not good estimation methods.
- They conflate the notions of effort and complexity. When we talk about a story's 'size,' we usually mean one of these two terms. Sometimes both. The thing is - these two things aren't the same. A work item may require a lot of effort but have very low complexity. The opposite may also be true. For instance, a task can be to implement many database views. The task is straightforward: select data table columns and present them as views with the right permissions. It is a straightforward task with minimal risk. However, such a task may take quite some time to complete due to the sheer scale of it. So, if one had to estimate this task in terms of effort, it would be given a high estimate value. If, however, it had to be estimated in terms of complexity or risk, it would have given a very low estimated value. The reverse also applies. In one real-life example, I had to implement business logic that took many re-writes and re-thinks to get right. The completed task involved only a few lines of code, but it had taken days of thinking, re-writing, and bug-fixing to get there. During the planning session, the team had conceded that this was a low-value task, based on the reasoning that it would only take a few lines of code to implement (which was correct). We had estimated based on effort but not complexity. Good estimation methods need to be specific about what it is that we are estimating and how to measure it. This leads us to the second point...
- They are subjective. Developers have different levels of skills and experience. Developer A may estimate a work item as small or simple, and, for them, that would be an accurate estimate. However, Developer B may consider the item as big or complex, which would be true for them based on their experience and skill set. The accuracy of the estimate depends on whoever is doing the actual work. The estimation then becomes a subjective and unreliable method and, therefore, useless. People will point out that this is where team discussion and the reaching of consensus for an estimate comes into play. But the consensus mechanism employed by planning poker and friends is, in fact, a coercion mechanism. Planning poker and friends makes developers accept estimates that reflect someone else's view of an item's size - Which brings us nicely to the third point.
- They fail to account for peer pressure. In most sprint planning sessions, estimate consensus shifts towards the estimate of the most experienced or influential developer in the meeting. This is a common scenario:
Dev A is a very skilled senior developer. Dev B is a junior developer with little experience in the application and business domain of the project. Dev A estimates a work item as a 3 (on a 1-10 scale). Dev B estimates the same item as a 7. Dev A will make coherent and persuasive arguments why that item should be a 3. Dev B lacks the experience to counter these arguments, so they will reluctantly agree that the item is a 3 (or will maybe settle at a 4). During development, Dev B has to deliver the item. They find it very difficult and time-consuming. The team wonders why an item estimated as a 3 takes so much time and effort. Stress and mistrust ensue.
In addition, some frameworks such as Scrum, time-box the planning meeting. This means that teams get pressured to reach consensus quickly, making developers even more susceptible to peer pressure. Such human factors also account for the fourth and final point.
4. They are inconsistent. Here is a simple experiment you can perform yourself. Ask a developer for an estimate on a task unrelated to their current project. Wait a few weeks, ensuring that the developer does not spend any time thinking about the task. Then ask again for an estimate for the same task. There is a good chance that you're going to get a different estimate. So, if the developer, the task, and the developer's understanding of the task remain the same, how can we be getting different estimates at different times? The answer is simply that our estimation is affected by our emotional and mental state. We've all been there: there are days when we think we can take on the whole world and days where we feel much less confident. Something that seems big or difficult today seems smaller and simpler tomorrow. We tend not to consciously think about our emotional and mental state when making decisions, but we are affected by them all the same. A good estimation method should account for such human factors that affect productivity and estimation ability.
It is for these reasons that these methods might not be fit for purpose. But if this is true, then why are they so popular? The simple answer is cultural acquisition:
- If our peers and seniors practice something, we tend to copy the practice unquestionably. This was the basis for the infamous five monkey experiment.
- In addition, teams and organizations need predictability; they need to feel in control of the future. So, we have velocity and burn-up/down charts and roadmaps. We can state that we have x story points remaining which are likely to be delivered by the final sprint, according to our current velocity. Sounds good, right? But it's all based on inconsistent, subjective, and unreliable estimation methods. When our charts don't match reality, we adjust them until they do. We 'calibrate' our estimates. We 'normalize' our story points. We 'add slack' into our sprints. Every time we do one of these things is an inadvertent admission that our estimation efforts have failed.
We need to improve our estimation methods so that they adhere to the rules of good estimation. A valid estimation method should yield estimates that are:
- Reliable. An estimate must reflect the actual work within a reasonable confidence interval.
- Objective. The same task should be estimated at the same value, regardless of who's giving the estimate.
- Consistent. Given nothing else has changed, an estimate should not change with time.
I call this the ROC principle. In the follow-up article, we'll examine techniques we can apply to ROC-ify our estimation. Until then, stay tuned.
Fred Heath is a software jack of all trades, living in Wales, UK. He is the author of Managing Software Requirements the Agile Way, available for purchase on Amazon.
