Overview
In another article, we discussed how to focus on all the task status but connected with the releases. Sometimes, this focus may eliminate the Completed or Total status which can be addressed by modifying the query in that article. But, what if we need to include the association of tasks with the requirements. As a result, we get four different combinations as follows that we may have to report for the team and management to retrospect for any behavioral patterns.
SQL Query
Given below is the query.
select T.RNAME, SUM(T.In_Progress) as WIP_COUNT, SUM(T.Not_Started) as NS_COUNT from
(
(select
R.TASK_STATUS_NAME,
Case when R.RELEASE_ID is null then "Unknown Release" else "Known Release" end as RNAME,
COUNT(R.TASK_ID) as Not_Started,
0 as In_Progress
from
SpiraTestEntities.R_Tasks as R
where
R.PROJECT_ID = ${ProjectId} and
R.IS_DELETED = False and
R.TASK_STATUS_NAME ="Not Started"
group by
R.TASK_STATUS_NAME, R.RELEASE_ID)
union
(select
R.TASK_STATUS_NAME,
Case when R.RELEASE_ID is null then "Unknown Release" else "Known Release" end as RNAME,
0 as Not_Started, COUNT(R.TASK_ID) as In_Progress
from
SpiraTestEntities.R_Tasks as R
where
R.PROJECT_ID = ${ProjectId} and
R.IS_DELETED = False and
R.TASK_STATUS_NAME ="In Progress"
group by
R.TASK_STATUS_NAME, R.RELEASE_ID)
union
(select
R.TASK_STATUS_NAME,
Case when R.REQUIREMENT_ID is null then "Unknown Requirement" else "Known Requirement" end as RNAME,
COUNT(R.TASK_ID) as Not_Started,
0 as In_Progress
from
SpiraTestEntities.R_Tasks as R
where
R.PROJECT_ID = ${ProjectId} and
R.IS_DELETED = False and
R.TASK_STATUS_NAME ="Not Started"
group by
R.TASK_STATUS_NAME, R.REQUIREMENT_ID)
union
(select
R.TASK_STATUS_NAME,
Case when R.REQUIREMENT_ID is null then "Unknown Requirement" else "Known Requirement" end as RNAME,
0 as Not_Started,
COUNT(R.TASK_ID) as In_Progress
from
SpiraTestEntities.R_Tasks as R
where
R.PROJECT_ID = ${ProjectId} and
R.IS_DELETED = False and
R.TASK_STATUS_NAME ="Not Started"
group by
R.TASK_STATUS_NAME, R.REQUIREMENT_ID)
) as T
group by
T.RNAME
order by
T.RNAME
Query Explanation
- This query combines two groups of ideas into two categories of inner queries.
- The first set of two inner queries focuses on counting the tasks associated with a known release or unknown release while aggregating counts by a specific status in its own separate columns.
- The second set of two inner queries replicates the earlier logic but focusing on the association with a known or unknown requirement.
- The outer query summarizes the results of the four inner queries.
- The where clause in each inner query
- filters for specific status (e.g.: TASK_STATUS_NAME = "In Progress")
- picks tasks that are not deleted (IS_DELETED = False)
- applies the current project selection (PROJECT_ID = ${ProjectId})
Output
Given below is the tabular data results.
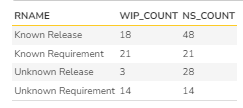
Graph
Given below is the graphical illustration.
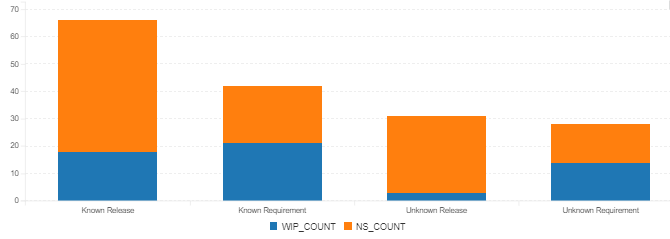
Graph Interpretation
- In any project (planned, adaptive, hybrid), the focus is to ensure that there is flow (this is the fundamental lean principle applicable to any type of project). As the goal is to ensure that any started task is completed, the focus in these graphs should be understanding why tasks remain in WIP state. This root cause may lead to many causes such as the schedule compression, resource optimization, task estimation accuracy, prioritization inflation, etc. While the graphs themselves will not give the reasons, it prompts one to use these KPIs to dig deeper.
- The next focus is also understanding why some tasks have not started. Unnecessary dependencies on other tasks, lack of resource leveling, resource unavailability, and task inflation among other things. So, digging deeper into the not started will help next.
- In both the above approaches, further analysis also may involve why certain tasks are not associated with a requirement or release and why certain stand alone tasks are consuming time preventing the definition of ready for sprint planning or definition of done for product increment delivery.