Risk Management Lifecycle
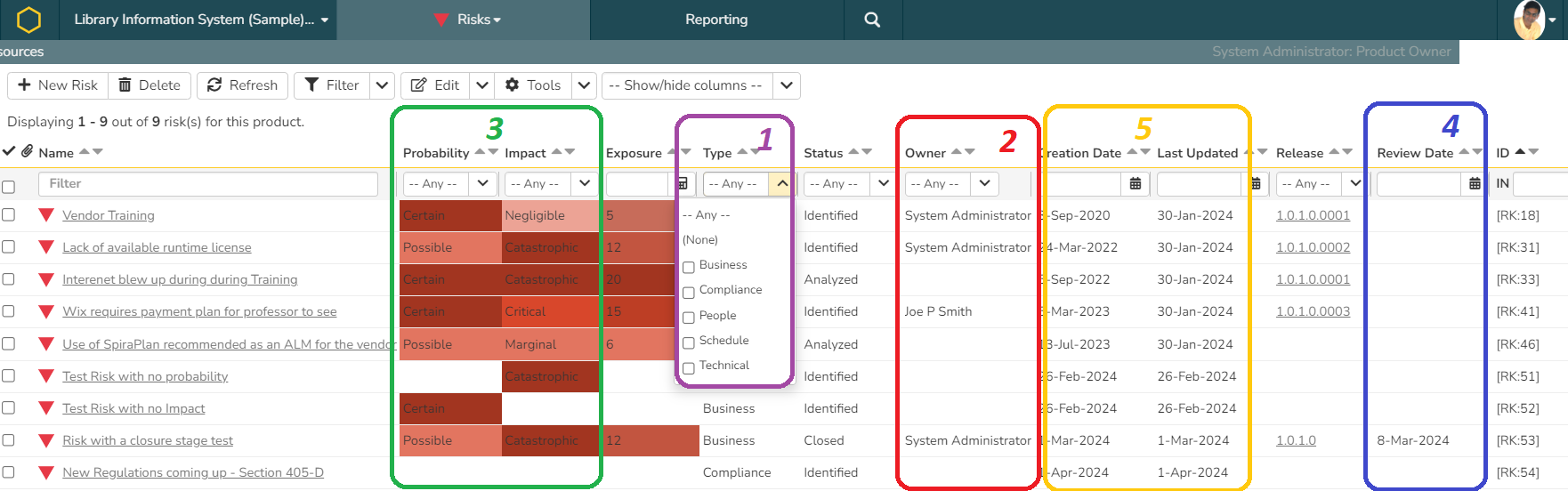
Typically, majority of the oversight on risk management lies only in addressing risks in the risk register. Such an analysis focuses on risk status like the identified, analyzed, evaluated, open, closed, and rejected. But, deeper in this set of risks may be other obvious ones hidden that may have to be looked at. Let us review them below using the diagram below for illustration.
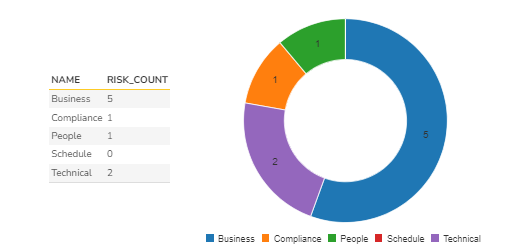
Good Practice 1: Missed Risks in a Risk Type
As part of the risk breakdown structure identified, risk types are identified in the risk template. One good "risk management" practice is to see if the team is somehow bias or inclined to identify certain types of risks potentially missing out on other risk types. For instance, we identified business, compliance, people, schedule, and technical risks (noted in as #1) in the diagram. But, if you look at the data, we have not identified any schedule risk at all.
Missed Risks against the Risk Types SQL Query
By running the SQL Query below, we can identify what the team fails to identify and dig deeper if there is any motivational or cognitive bias or missed opportunities exist.
select
RT.NAME,
COUNT(R.RISK_ID) as RISK_COUNT
from
SpiraTestEntities.R_RiskTypes as RT
join
SpiraTestEntities.R_Projects as P on P.PROJECT_TEMPLATE_ID = RT.PROJECT_TEMPLATE_ID
left join
SpiraTestEntities.R_Risks as R on
R.PROJECT_ID = P.PROJECT_ID and
R.IS_DELETED = False and
R.RISK_TYPE_ID = RT.RISK_TYPE_ID
where
P.PROJECT_ID = ${ProjectId}
group by
RT.NAME
Query Explanation
- In the select clause, we are counting the risk types identified in the workflow and aggregate risks listed in the risk register.
- In the first join with the Projects table, we are matching against the project template as templates live outside of the product and we need to match only risks identified for the specific template used by the product
- In the second join, we invoke the left join as the goal is to identify risk types that may not risk in the risk register. Further, we limit the query set by connecting the project id, removing deleted risks, and matching against the risk_type with the template.
- In the where clause we connect with the current project selected.
- The group by clause is required to aggregate the list in the select clause
Output & Graph
Given below is the data output and the graph.
Good Practice 2: Unassigned Owner for a Risk
It is important to ensure risks have their own owners (R owner in RACI). Frequently, project managers, scrum masters, business analysts, system analysts, or product managers try to take it on themselves forgetting that they are the accountable (A owner in the RACI) without clearly identifying a risk owner. As a result, the unassigned risks are frequently not evaluated before it is too late. The unassigned owners are identified in the risk register as #2 in the diagram above.
Unassigned Risk Owners SQL Query
By running the SQL Query below, we can identify what risks are have been progressing through the lifecycle so that they can be addressed before it is too late.
select
"No Owner" as TYPE,
R.RISK_ID,
R.NAME
from
SpiraTestEntities.R_Risks as R
where
R.PROJECT_ID = ${ProjectId} and
R.IS_DELETED = False and
R.OWNER_NAME is null
Query Explanation
- In the select clause, we are adding a "No Owner" as a computed column and brings additional risk details (like ID and Name)
- The where clause applies the current product selection, removes the deleted, and applies the "null" check against the owner_name
Output

Good Practice 3: Missing Impact or Probability for a Risk
Sometimes, smaller organizations may combine the analysis and evaluation stage concurrently and sometimes they may follow specific workflow steps. In these cases, it is possible that sometimes the true evaluation is not possible because either the probability or the impact is not recorded. In order to prioritize risks by risk scores or exposure, both these elements are required. These sections are identified as #3 in the diagram.
Unassigned Risk Impact or Unassigned Risk Probability SQL Query
select
R.RISK_ID,
R.NAME,
R.RISK_PROBABILITY_NAME,
R.RISK_IMPACT_NAME
from
SpiraTestEntities.R_Risks as R
where
R.PROJECT_ID = ${ProjectId} and
R.IS_DELETED = False and
(R.RISK_IMPACT_NAME is null or R.RISK_PROBABILITY_NAME is null)
Query Explanation
- This query is straightforward except that we apply the OR condition in the last where clause statement
Output

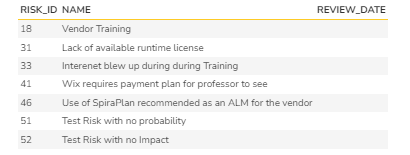
Good Practice 4: Missing Review Date
Another pattern that can be checked as part of the good practice is when owners are identified, risks are qualified for probability and impact but do not have a review date. This is pattern that can often be seen by inconsistent RACI practices, such as R and A owner being the same. This pattern manifests as not having someone validate if the risk probability or risk impact have increased or if the risk has to be retired or closed. For more information on RACI, please consult the article RACI Errors by Rajagopalan(2014). This is identified by #4 in the diagram.
Unassigned Risk Review Date
select
R.RISK_ID,
R.NAME,
R.REVIEW_DATE
from
SpiraTestEntities.R_Risks as R
where
R.PROJECT_ID = ${ProjectId} and
R.IS_DELETED = False and
R.REVIEW_DATE is null
Query Explanation
- This query is straightforward except that we apply the null constraint on review date
- It is possible that you can bring the "R.RISK_IMPACT_NAME is not null and R.RISK_PROBABILITY_NAME is not null" as an additional clause in the where clause. But, this has been removed primarily because smaller organizations may not have filled one of them and if we apply this clause we may miss the opportunity to evaluate the review date for such risks.
Output
Given below is the report.
Good Practice 5: Long Review Cycle
One more pattern that can be evaluated in risk life cycle is the time it takes to constantly update the risks. This is done mostly as part of the monitoring. This practice can help in documented controls to evaluate the risks on an ongoing basis. This review cycle can be evaluated in two ways.
- The number of days elapsed between the date the risk was created and the last time it was updated
- The number of days elapsed between the last update date till today (current day)
Long Review Cycle Query
Given below is the query
select
R.RISK_ID,
R.NAME,
R.CREATION_DATE,
R.LAST_UPDATE_DATE,
DiffDays(R.CREATION_DATE, R.LAST_UPDATE_DATE) as MONITOR_FREQ,
DiffDays(R.LAST_UPDATE_DATE, CurrentDateTime()) as MISSED_SINCE_LASTUPDATE
from
SpiraTestEntities.R_Risks as R
where
R.PROJECT_ID = ${ProjectId} and
R.IS_DELETED = False
Query Explanation
- The query is a simple one except that the select clauses uses DiffDays function to compute the difference between two days.
- The MONITOR_FREQ is the difference between the date the risk was first created till the time it was last updated.
- The MISSED_SINCE_LASTEUPDATE is the difference between the last updated date and current date.
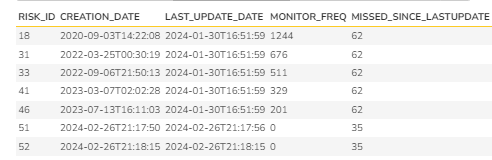
Output
Given below is the output
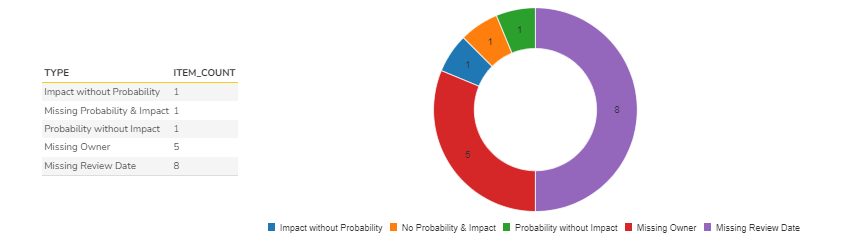
Graphing Good Practices 2, 3, and 4
- We already showed a graph for the first good practice. But, for items 2, 3, and 4, we showed the data in the report format.
- The final good practice is not a good candidate for graphing purposes as when you bring the number of days elapsed, the duration may be very high. It is possible to apply the "DiffDays(R.CREATION_DATE, CurrentDateTime())>14" to evaluate how long beyond 14 days (2 weeks) a risk has not been paid attention to. But, such practices may not be good practices as depending upon the risk type and the organization, risks may have to be reviewed every day or can be ignored for several weeks.
- However, if query is slightly modified, the metrics from good practices 2, 3, and 4 can be monitored graphically.
Combined SQL Query
(select
"Missing Owner" as TYPE,
count(R.RISK_ID) as ITEM_COUNT
from
SpiraTestEntities.R_Risks as R
where
R.PROJECT_ID = ${ProjectId} and R.IS_DELETED = False and R.OWNER_NAME is null
group by R.OWNER_NAME)
union
(select
"Impact without Probability" as TYPE,
COUNT(R.RISK_ID) as ITEM_COUNT
from
SpiraTestEntities.R_Risks as R
where
R.PROJECT_ID = ${ProjectId} and R.IS_DELETED = False and
R.RISK_IMPACT_NAME is not null and R.RISK_PROBABILITY_NAME is null)
union
(select
"Probability without Impact" as TYPE,
COUNT(R.RISK_ID) as ITEM_COUNT
from
SpiraTestEntities.R_Risks as R
where
R.PROJECT_ID = ${ProjectId} and R.IS_DELETED = False and
R.RISK_IMPACT_NAME is null and R.RISK_PROBABILITY_NAME is not null)
union
(select
"No Probability & Impact" as TYPE,
COUNT(R.RISK_ID) as ITEM_COUNT
from
SpiraTestEntities.R_Risks as R
where
R.PROJECT_ID = ${ProjectId} and R.IS_DELETED = False and
R.RISK_IMPACT_NAME is null and R.RISK_PROBABILITY_NAME is null)
union
(select
"Missing Review Date" as TYPE,
COUNT(R.RISK_ID) as ITEM_COUNT
from
SpiraTestEntities.R_Risks as R
where
R.PROJECT_ID = ${ProjectId} and R.IS_DELETED = False and
R.REVIEW_DATE is null)
Output and Graph
Given below is the combined data for further review.