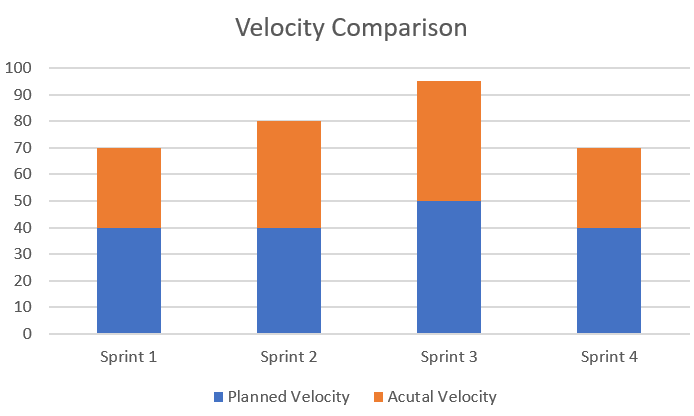
Example of a Velocity Chart
Set the Planned Points
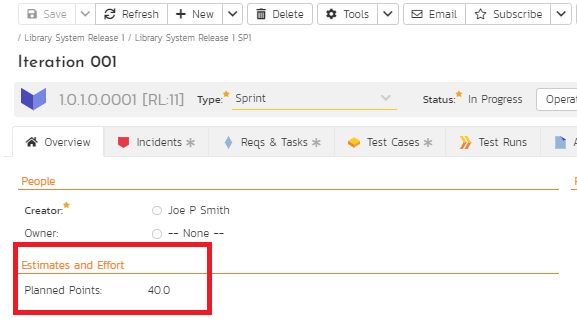
In order to deliver this velocity chart, there is one major pre-requisite. This pre-requisite is that the standard field called "Planned Points" at the release level is set. As soon sprint or iteration planning event is complete, the team should know the cumulative point commitment for the specific sprint. This committed velocity for the sprint should be updated as the planned estimate.
Setting up Multiple Sprints
For illustrative purposes, four sprints are set up here. The planned velocity comes from the sprint planning exercise as mentioned before. The user stories committed as part of the sprints are summed up in the required estimate.

Please ignore the dates in this example. The important things are the planned points, required points, release type (sprint) and release status (In Progress). These are relevant to the SQL query.
Creating the SQL Query for the Graph
- From the administration panel, go to the "Edit Graph"
- Add a new graph and give it a name.
- Write the SQL Query as follows
- Save the Graph
- Add it to the Reporting Panel
select R.NAME,
R.PLANNED_POINTS as PLANNED_VELOCITY,
R.REQUIREMENT_POINTS AS ACTUAL_VELOCITY
from
SpiraTestEntities.R_Releases as R
where
R.PROJECT_ID = ${ProjectId} and
R.PLANNED_POINTS IS NOT NULL and
R.REQUIREMENT_POINTS IS NOT NULL and
R.RELEASE_TYPE_NAME = "Sprint" and
R.RELEASE_STATUS_NAME = "In Progress"
Explanation of the SQL
- The entity "Releases" contains two fields. One of this is the planned estimate. The other is a cumulative story point value of all the requirements associated with the release.
- The RELEASE_STATUS_NAME is used to show only releases in progress in this illustration. This supports parallel releases. But, if releases are marked closed, then, you may want to look at other release status names.
- The RELEASE_TYPE_NAME is used to filter only "Sprints" to disallow bringing other release types like major release, minor release, and phase.
- The graph wouldn't render nicely if there is no planned points or story points with the requirements. associated. So, we add the clause "PLANNED POINTS IS NOT NULL" and REQUIRED_POINTS IS NOT NULL to remove any sprint from graphical consideration when these point values are not filled.
- The PROJECT_ID = ${ProjectId} is used to ensure that the graph is mapped to the specific project selected.
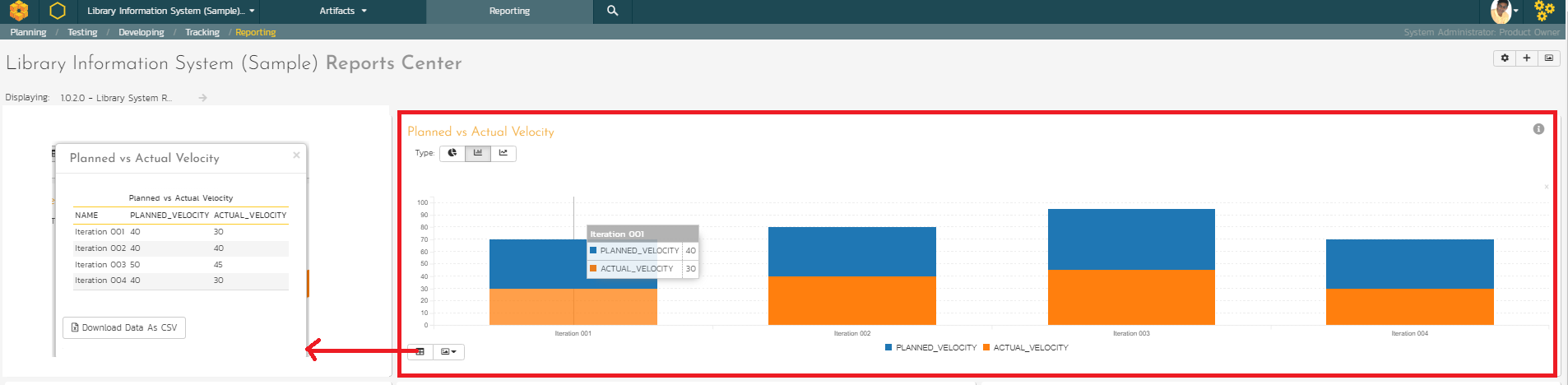
Actual Output
Here is the actual output for the illustrative data used in this example. Please note that the "Display Data Grid" can be used to look at the data for this graph as shown here. Note that the release picker at the far left corner is not relevant because we didn't bring the release id itself in the SQL query.
Some Best Practice Process considerations
Typically, only actual velocity delivered is graphed. This is already supported in the Project Dashboard. One main reason is that undelivered requirements are put back to the product backlog as they may require a) risk adjustment due to non-delivery or b) prioritization may have changed at the end of the sprint. When these undelivered user stories are remapped to another sprint in the immediate future or later, then, the required points no longer reflect the actual velocity for the previous sprint. If the focus is on comparing estimation accuracy, then, the retrospective event can immediately capture the lessons learned behind such estimate comparison.