GUI testing is often considered the most difficult part of the test pyramid. UI tests take time to develop and require significant time to execute and maintain. However since UI tests are end-to-end tests they provide visible evidence of system quality and operability. If any of UI tests fail for real reasons then it is a serious indicator that the system can not be released or requires repair. So, let's re-formulate the question posed at the beginning of this article. Can model-based testing make GUI testing less difficult? I.e reduce costs and allow finding more important defects earlier in the application life cycle? Let's try to answer the question.
Theory
What can we expect from model-based testing approach? Here is the list of artifacts we consider most important for GUI testing.
- Test cases automatically generated from the model.
- Test cases manually derived from the model.
- Model and requirements coverage metrics.
Automated Test Case Generation
What if we had a tool which could automatically generate tests from a model? What would we require from such a tool?
Widely accepted approach to modeling behavior of UI systems is using finite state machines. Here is an example of UML State Machine we created for our Library Information System sample application (LIS).
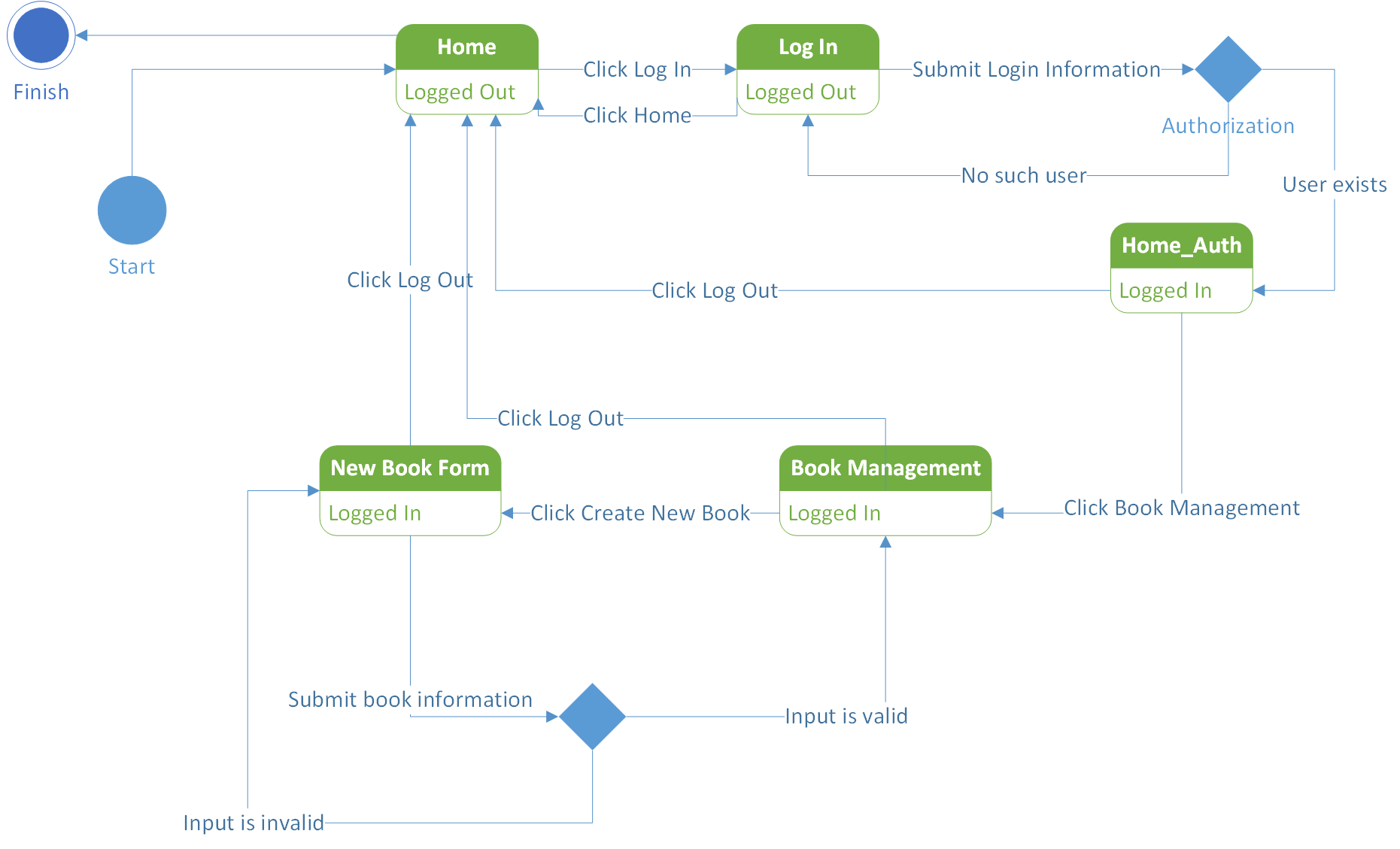
Actually this diagram models just a subset of LIS behavior. It has 5 states and 13 transitions.
Assume that we have a simple test case generator which can produce test cases covering all different paths in the graph from start to finish state and no longer than a defined number of transitions.
Since the length of the most interesting path (user logs in, adds a new book and logs out) is 8 we'll use this value. After running the generator we'll find out that the number of paths from start to finish no longer than 8 transitions is 33. Here is the list.
('start', 'home', 'finish')
('start', 'home', 'login', 'home_auth', 'home', 'finish')
('start', 'home', 'login', 'home_auth', 'home', 'login', 'home_auth', 'home', 'finish')
('start', 'home', 'login', 'home_auth', 'home', 'login', 'home', 'finish')
('start', 'home', 'login', 'home_auth', 'home', 'login', 'login', 'home', 'finish')
('start', 'home', 'login', 'home_auth', 'book_management', 'new_book', 'new_book', 'home', 'finish')
('start', 'home', 'login', 'home_auth', 'book_management', 'new_book', 'home', 'finish')
('start', 'home', 'login', 'home_auth', 'book_management', 'new_book', 'book_management', 'home', 'finish')
('start', 'home', 'login', 'home_auth', 'book_management', 'home', 'finish')
('start', 'home', 'login', 'home_auth', 'book_management', 'home', 'login', 'home', 'finish')
('start', 'home', 'login', 'home', 'finish')
('start', 'home', 'login', 'home', 'login', 'home_auth', 'home', 'finish')
('start', 'home', 'login', 'home', 'login', 'home_auth', 'book_management', 'home', 'finish')
('start', 'home', 'login', 'home', 'login', 'home', 'finish')
('start', 'home', 'login', 'home', 'login', 'home', 'login', 'home', 'finish')
('start', 'home', 'login', 'home', 'login', 'login', 'home_auth', 'home', 'finish')
('start', 'home', 'login', 'home', 'login', 'login', 'home', 'finish')
('start', 'home', 'login', 'home', 'login', 'login', 'login', 'home', 'finish')
('start', 'home', 'login', 'login', 'home_auth', 'home', 'finish')
('start', 'home', 'login', 'login', 'home_auth', 'home', 'login', 'home', 'finish')
('start', 'home', 'login', 'login', 'home_auth', 'book_management', 'new_book', 'home', 'finish')
('start', 'home', 'login', 'login', 'home_auth', 'book_management', 'home', 'finish')
('start', 'home', 'login', 'login', 'home', 'finish')
('start', 'home', 'login', 'login', 'home', 'login', 'home_auth', 'home', 'finish')
('start', 'home', 'login', 'login', 'home', 'login', 'home', 'finish')
('start', 'home', 'login', 'login', 'home', 'login', 'login', 'home', 'finish')
('start', 'home', 'login', 'login', 'login', 'home_auth', 'home', 'finish')
('start', 'home', 'login', 'login', 'login', 'home_auth', 'book_management', 'home', 'finish')
('start', 'home', 'login', 'login', 'login', 'home', 'finish')
('start', 'home', 'login', 'login', 'login', 'home', 'login', 'home', 'finish')
('start', 'home', 'login', 'login', 'login', 'login', 'home_auth', 'home', 'finish')
('start', 'home', 'login', 'login', 'login', 'login', 'home', 'finish')
('start', 'home', 'login', 'login', 'login', 'login', 'login', 'home', 'finish')You can easily reproduce the result with this simple Python program.
import matplotlib.pyplot as plt
import networkx as nx
G = nx.DiGraph()
G.add_edge("start", "home", label="start")
G.add_edge("home", "login", label="login")
G.add_edge("login", "home", label="home")
G.add_edge("login", "home_auth", label="valid user")
G.add_edge("login", "login", label="no such user")
G.add_edge("home_auth", "book_management", label="book management")
G.add_edge("book_management", "new_book", label="new book")
G.add_edge("new_book", "book_management", label="valid data")
G.add_edge("new_book", "new_book", label="bad data")
G.add_edge("home_auth", "home", label="logout")
G.add_edge("book_management", "home", label="logout")
G.add_edge("new_book", "home", label="logout")
G.add_edge("home", "finish", label="finish")
max_transitions = 8
paths = [("start",)]
new_paths = []
for i in range(0, max_transitions):
for p in paths:
node = p[-1]
neighbors = G.successors(node)
if len(neighbors) == 0:
new_paths.append(p)
for nb in neighbors:
new_paths.append(p + (nb,))
paths = new_paths.copy()
new_paths.clear()
c = 0
for p in paths:
if p[-1] == "finish":
print(p)
c = c + 1
print("Number of all paths of length " + str(max_transitions))
print(len(paths))
print("Number of paths ending with 'finish'")
print(c)Let's remove just one transition from the state machine - back link from login to home page and run the generator again. We'll get that the number of paths we need is 13. This is a perfect illustration how tiny change in a state machine influences the number of generated test cases. Compare 33 and 13.
Next observation. If we have 33 test cases and every test case is executed about 20 seconds (pretty much realistic estimate) then the whole test set will run for 11 minutes.
If we'll generate test cases using the approach described above for the complete model of LIS we'll get a test set that will run for a few hours. If approximate the calculations to a real life application modeled with tens of states and hundreds of transitions we'll quickly realize that our test set execution time is unacceptable.
And the situation becomes even worse when we bring data (different user logins, book names) onto the stage.
What to do?
If you will look at the generated paths you will notice that many of them have no or little practical sense. For example:
('start', 'home', 'login', 'home', 'login', 'home', 'login', 'home', 'finish')
('start', 'home', 'login', 'login', 'home', 'login', 'login', 'home', 'finish')
('start', 'home', 'login', 'login', 'login', 'login', 'login', 'home', 'finish')This is merely switching back and fourth between home and login pages.
So, to reduce the number of generated test cases one needs to implement efficient test case selection algorithm to filter out inadequate scenarios. Unfortunately there is no best algorithm for test selection, it is always model and application specific. The main goal of test selection is to ensure that most important paths are covered and the size of the generated test set is small enough to produce acceptable execution times.
There is a trade-off:
- without test case filtering generated test set may be too big and slow,
- implementation of efficient test case selection algorithm is a complex and time consuming task itself.
Both alternatives may lead to inappropriate costs of using a model-based approach to UI test automation. But we do not have to automate test case generation 100%. If we'll include a man in the process we can do better.
Manual Test Case Selection
A test engineer can use the model be it finite state machine or another type to produce test sequences manually. In our LIS example the test engineer may propose the following sequences without using any kind of a generator:
# successful login
('start', 'home', 'login', 'home_auth', 'home', 'finish')
# invalid login
('start', 'home', 'login', 'login', 'home', 'finish')
# add a book
('start', 'home', 'login', 'home_auth', 'book_management', 'new_book', 'book_management', 'home', 'finish')
# invalid book data
('start', 'home', 'login', 'home_auth', 'book_management', 'new_book', 'new_book', 'home', 'finish')These 4 sequences cover all states, 12 of 13 transitions and implement all most probable usage scenarios. Such a test set will run for less than 2 minutes instead of 11 minutes for auto generated test set from the previous section.
So, manual approach to test case selection may be a good idea. Coupled with automatic generation of a test script implementing the test case it can be a powerful solution.
Model and Requirements Coverage
When you have a model and a test set (generated or manually produced) you may want to determine how adequate this test set checks the application. To help with such an analysis build model and requirements coverage metrics.
For a model one may count the number of states and transitions hit by a test set. Additional metric is the number of covered transition pairs. Of course this is not a complete list, but most popular examples.
Let's count model coverage metrics for two LIS test sets we built above.
# LIS Auto-Generated, 33 test cases
covered_states = 5 # of 5, coverage is 100%
covered_transitions = 13 # of 13, coverage is 100%
covered_transition_pairs = 28 # of 28, coverage is 100%
# LIS Manual, 4 test cases
covered_states = 5 # of 5, coverage is 100%
covered_transitions = 12 # of 13, coverage is 92%
covered_transition_pairs = 15 # of 28, coverage is 53%
Here is the simple Python code for counting total number of transitions in a graph and the number of covered transitions. We show it here for illustration purposes only, it is not optimal and not ready for production use.
# all transition pairs
pair_count = 0
for e in G.edges(data=True):
neighbors = G.successors(e[1])
pair_count += len(neighbors)
print("Transition pair count")
print(pair_count)
# list of test cases
paths = [('start', 'home', 'login', 'home_auth', 'home', 'finish'),
('start', 'home', 'login', 'login', 'home', 'finish'),
('start', 'home', 'login', 'home_auth', 'book_management', 'new_book', 'book_management', 'home', 'finish'),
('start', 'home', 'login', 'home_auth', 'book_management', 'new_book', 'new_book', 'home', 'finish')]
# covered transitions pairs
covered_pairs = []
for p in paths:
node_count = len(p)
for i in range(0, node_count - 2):
covered_pairs.append((p[i], p[i + 1], p[i + 2]))
print("Covered transition pairs")
print(len(set(covered_pairs)))Proposed Solution
At Inflectra we developed a few ideas of how to approach model-based testing problem in a way that is easy to use and optimized specifically for UI testing domain.
The approach we propose consists of several steps. First step is to build a tree of windows and controls. A window can be a physical or logical grouping of controls. For each control id and type must be specified. Here is an example for LIS application.
- Model
- Home
- LogIn
- Username [edit]
- Password [edit]
- LogIn [button]
- Home [link]
- Home_Auth
- Book_Management [link]
- LogOut [link]
- Book_Management
- New_Book [button]
- Books [table]
- LogOut [link]
- New_Book_Form
- Name [edit]
- Author [dropdown]
- Genre [dropdown]1
- Insert [button]
- LogOut [link]
The process of building the model can be manual or automated. For example the model can be obtained from a formal specification of an application or recorded with a test automation tool.
Type of a UI control determines which actions can be applied to this control and which properties can be read or modified. Having such a model a test engineer is capable of building test case specifications even before application actually exists.
Thus the second step is to create test cases. Let's Look at two test cases for LIS. We'll be using JavaScript-based notation.
Test Case 1
This test case checks successful authorization for a given pair of username/password.
Home["LogIn"].Click();
LogIn["Username"].SetText('<username>');
LogIn["Password"].SetText('<password>');
LogIn["LogIn"].Click();
Assert(Home_Auth["LogOut"].Visible);
Home_Auth["LogOut"].Click();
Assert(Home["LogIn"].Visible);Test Case 2
This test case creates a new book and checks it was successfully added.
Home["LogIn"].Click();
LogIn["Username"].SetText('<username>');
LogIn["Password"].SetText('<password>');
LogIn["Login"].Click();
Home_Auth["Book_Management"].Click();
Book_Management["New_Book"].Click();
New_Book_Form["Name"].SetText('<book title>');
New_Book_Form["Author"].SetText('<book author>');
New_Book_Form["Genre"].SetText('<book genre>');
New_Book_Form["Insert"].Click();
Assert(Book_Management["Books"].ContainsRow('<book title>', '<book author>', '<book genre>'));
New_Book_Form["LogOut"].Click();When test prototypes are ready the remaining step is to record object locators that will be used to find controls during script playback.
Recording of locators can be automated. For example. when a test case is executed for the first time an automation tool may prompt user to point to controls which can not be located by the tool. Where automation is not possible a test engineer can calculate locators manually.
Also test scenarios can be built as data-driven from the beginning. Such values as <username>, <password>, <book title>, <book author> and <book genre> can be test parameters and loaded from spreadsheets.
We now have a formula of the model-based approach proposed by Inflectra:
Model + Test Scenarios + Locators + Data = Executable Test Set
Within described framework there is an opportunity to have working tests almost immediately after application interface is developed or even earlier. Thus the code written can be immediately tested and defects found.
Conclusions
So, can model-based testing make GUI testing less difficult? Short answer is yes, it can. The longer answer is "it can if used smart and if applicable". It is relatively easy and tempting to generate a test set that is performing a lot of dummy testing and runs for hours. Also if you go model-based way you must have well established processes within a company which align efforts different groups of people are undertaking. The process must allow not only to create a test set but also be friendly to constant changes in developed software. A company may be just not ready for model-based testing and even for test automation in general.
There are potential issues of using model-based approach in GUI testing. Let's list some of them.
- Generation of a test set with unacceptable execution time.
- Efforts for building a model, test cases selection algorithm, test script generation procedure can be too high and thus too expensive.
- There is a lack of skills within a company to adopt test automation.
On the other hand there are potential benefits.
- Creation of cheaper and better tests.
- Opportunity to test earlier in the application life cycle (shift-left).
- Improvement of communication between stakeholders.
- Structured testing process.
To see if model-based testing works in your project or not we suggest to start small: create a tiny model, create several test cases, generate test scripts, execute, measure effectiveness. If may take significant efforts to establish a process but then be easy to maintain and enhance the test coverage.